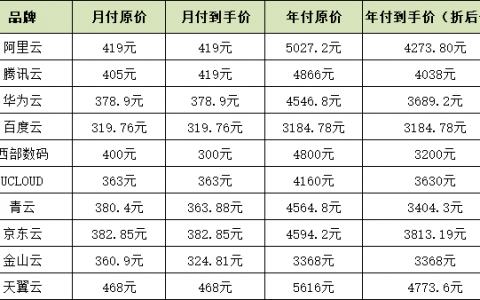
Kubernetes架构图
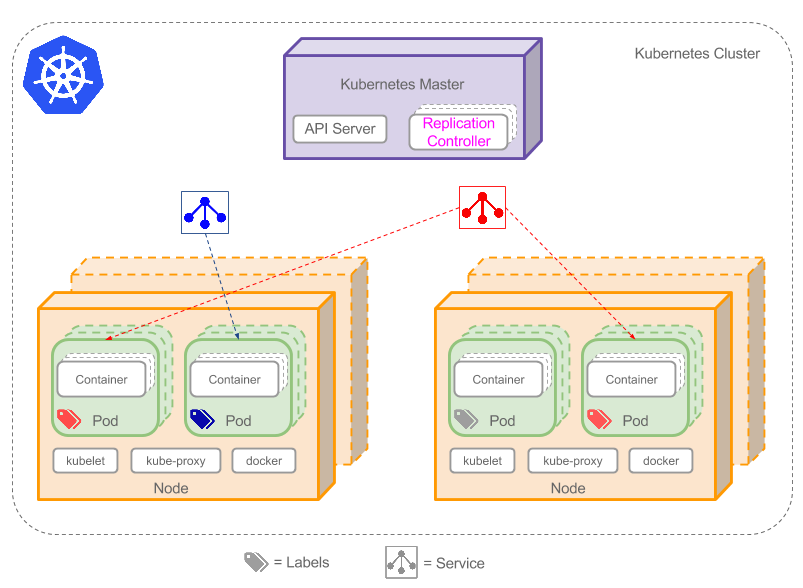
上图可以看到如下组件,使用特别的图标表示Service和Label:
-
- Pod
- Container(容器)
- Label(标签)
- Replication Controller(复制控制器)
- Service(服务)
- Node(节点)
- Kubernetes Master(Kubernetes主节点)
一,Pod
Pod 是Kubernetes的基本操作单元,也是应用运行的载体。整个Kubernetes系统都是围绕着Pod展开的,比如如何部署运行Pod、如何保证Pod的数量、如何访问Pod等。另外,Pod是一个或多个机关容器的集合,提供了一种容器的组合的模型。
Pod(上图绿色方框)安排在节点上,包含一组容器和卷。同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。Pod是短暂的,不是持续性实体。
-
- Pod是短暂的,pod重建的时候数据会丢失,对于需要持久化的数据,因为Kubernetes支持卷的概念,故可以使用持久化的卷类型。这样就能持久化容器数据使其能够跨重启而存在。
- 创建Pod时可以手动创建单个Pod,也可以使用Replication Controller使用Pod模板创建出多份拷贝。
- Pod是短暂的,那么重启时IP地址可能会改变,那么怎么才能从前端容器正确可靠地指向后台容器呢?这时可以使用Service。
Pods提供两种共享资源:网络和存储。
网络:
每个Pod被分配一个独立的IP地址,Pod中的每个容器共享网络命名空间,包括IP地址和网络端口。
Pod内的容器可以使用localhost相互通信。
当Pod中的容器与Pod 外部通信时,他们必须协调如何使用共享网络资源(如端口)。
存储:
Pod可以指定一组共享存储volumes。
Pod中的所有容器都可以访问共享volumes,允许这些容器共享数据。
volumes 还用于Pod中的数据持久化,以防其中一个容器需要重新启动而丢失数据
1, pod基本操作
创建 kubectl create -f xxx.yaml
查询 kubectl get pod yourPodName kubectl describe pod yourPodName
删除 kubectl delete pod yourPodName kubectl delete -f xxx.yaml
更新 kubectl replace /path/to/yourNewYaml.yml
2, Pod与容器
在Docker中,容器是最小的处理单元,增删改查的对象是容器,容器是一种虚拟化技术,容器之间是隔离的,隔离是基于Linux Namespace实现的。而在Kubernetes中,Pod包含一个或者多个相关的容器,Pod可以认为是容器的一种延伸扩展,一个Pod也是一个隔离体,而Pod内部包含的一组容器又是共享的(包括PID、Network、IPC、UTS)。除此之外,Pod中的容器可以访问共同的数据卷来实现文件系统的共享。
3,Pod与Controller
Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力。如果一个Node故障,Controller就能自动将该节点上的Pod调度到其他健康的Node上
4,pod与镜像
在kubernetes中,镜像的下载策略为:
Always:每次都下载最新的镜像
Never:只使用本地镜像,从不下载
IfNotPresent:只有当本地没有的时候才下载镜像
Pod被分配到Node之后会根据镜像下载策略进行镜像下载,可以根据自身集群的特点来决定采用何种下载策略。无论何种策略,都要确保Node上有正确的镜像可
5,pod与yaml
通过yaml文件,可以在Pod中设置:
启动命令,如:spec–>containers–>command;
环境变量,如:spec–>containers–>env–>name/value;
端口桥接,如:spec–>containers–>ports–>containerPort/protocol/hostIP/hostPort(使用hostPort时需要注意端口冲突的问题,不过Kubernetes在调度Pod的时候会检查宿主机端口是否冲突,比如当两个Pod均要求绑定宿主机的80端口,Kubernetes将会将这两个Pod分别调度到不同的机器上);
Host网络,一些特殊场景下,容器必须要以host方式进行网络设置(如接收物理机网络才能够接收到的组播流),在Pod中也支持host网络的设置,如:spec–>hostNetwork=true;
数据持久化,如:spec–>containers–>volumeMounts–>mountPath;
重启策略,当Pod中的容器终止退出后,重启容器的策略。这里的所谓Pod的重启,实际上的做法是容器的重建,之前容器中的数据将会丢失,如果需要持久化数据,那么需要使用数据卷进行持久化设置。Pod支持三种重启策略:Always(默认策略,当容器终止退出后,总是重启容器)、OnFailure(当容器终止且异常退出时,重启)、Never(从不重启)
6,Pod生命周期
Pod被分配到一个Node上之后,就不会离开这个Node,直到被删除。当某个Pod失败,首先会被Kubernetes清理掉,之后ReplicationController将会在其它机器上(或本机)重建Pod,重建之后Pod的ID发生了变化,那将会是一个新的Pod。所以,Kubernetes中Pod的迁移,实际指的是在新Node上重建Pod。
二,Replication Controller 副本控制
Replication Controller确保任意时间都有指定数量的Pod“副本”在运行。如果为某个Pod创建了Replication。Controller并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它。
当创建Replication Controller时,需要指定两个东西:
Pod模板:用来创建Pod副本的模板
Label:Replication Controller需要监控的Pod的标签。RC与Pod的关联是通过Label来实现的。
rc.yml案例:
apiVersion: v1
kind: ReplicationController
metadata: #设置rc的元数据
name: frontend
labels:
name: frontend
spec:
replicas: 3 #设置Pod的具体数量
selector: #通过selector来匹配相应的Pod的label
name: frontend
template: #设置Pod的模板
metadata:
labels:
name: frontend
spec:
containers:
- name: frontend
image: kubeguide/guestbook-php-frontend:latest
imagePullPolicy: IfNotPresent #镜像拉取策略,分为Always,Never,IfNotPresent,默认是Always
env :
- name : GET_HOSTS_FROM
value : env
ports:
- containerPort: 80
yaml字段的含义:
spec.replicas:副本数量3
spec.selector:RC通过spec.selector来筛选要控制的Pod
spec.template:这里写Pod的定义(但不需要apiVersion和kind)
spec.template.metadata.labels:Pod的label,可以看到这个label与spec.selector相同
这个文件的意思:
定义一个RC对象,它的名字是frontend(metadata.name:frontend),保证有3个Pod运行(spec.replicas:3),Pod的镜像是kubeguide/guestbook-php-frontend:latest(spec.template.spec.containers.image:kubeguide/guestbook-php-frontend:latest)
关键在于spec.selector与spec.template.metadata.labels,这两个字段必须相同,否则下一步创建RC会失败。(也可以不写spec.selector,这样默认与spec.template.metadata.labels相同)
RC的常用操作命令:
通过kubectl创建RC
# kubectl create -f rc.yaml
查看RC具体信息
# kubectl describe rc frontend
通过RC修改Pod副本数量(需要修改yaml文件的spec.replicas字段到目标值,然后替换旧的yaml文件)
# kubectl replace -f rc.yaml
或
# kubect edit replicationcontroller frontend
对RC使用滚动升级,来发布新功能或修复BUG
# kubectl rolling-update frontend –image=kubeguide/guestbook-php-frontend:latest
当Pod中只有一个容器时,通过–image参数指定新的Tag完成滚动升级,但如果有多个容器或其他字段修改时,需要指定yaml文件
# kubectl rolling-update frontend -f FILE.yaml
如果在升级过程中出现问题(如发现配置错误、长时间无响应),可以使用CTRL+C退出,再进行回滚
# kubectl rolling-update frontend –image=kubeguide/guestbook-php-frontend:latest –rollback
回滚。但如果升级完成后出现问题(比如新版本程序出core),此命令就无能为力了。我们需要使用同样方法,利用原来的镜像,“升级”为旧版本。
三,Deployment
更加方便的管理Pod和Replica Set
k8s是一个高速发展的项目,在新的版本中,官方推荐使用Replica Set和Deployment来代替RC。那么它们优势在哪里,我们来看一看:
(1)RC只支持基于等式的selector(env=dev或environment!=qa),但Replica Set还支持新的,基于集合的selector(version in (v1.0, v2.0)或env notin (dev, qa)),这对复杂的运维管理很方便。
(2)使用Deployment升级Pod,只需要定义Pod的最终状态,k8s会为你执行必要的操作,虽然能够使用命令# kubectl rolling-update完成升级,但它是在客户端与服务端多次交互控制RC完成的,所以REST API中并没有rolling-update的接口,这为定制自己的管理系统带来了一些麻烦。
(3)Deployment拥有更加灵活强大的升级、回滚功能。
目前,Replica Set与RC的区别只是支持的selector不同,后续肯定会加入更多功能。Deployment使用了ReplicaSet,它是更高一层的概念。除非用户需要自定义升级功能或根本不需要升级Pod,在一般情况下,我们推荐使用Deployment而不直接使用Replica Set。
Deployment的一些基础命令;
$ kubectl describe deployments #查询详细信息,获取升级进度 $ kubectl rollout pause deployment/nginx-deployment2 #暂停升级 $ kubectl rollout resume deployment/nginx-deployment2 #继续升级 $ kubectl rollout undo deployment/nginx-deployment2 #升级回滚 $ kubectl scale deployment nginx-deployment --replicas 10 #弹性伸缩Pod数量
使用子命令create,创建Deployment
# kubectl create -f deployment.yaml –record
注意–record参数,使用此参数将记录后续创建对象的操作,方便管理与问题追溯
使用子命令edit,编辑spec.replicas/spec.template.spec.container.image字段,完成deployment的扩缩容与滚动升级(这要比子命令rolling-update速度快很多)
# kubectl edit deployment hello-deployment
使用rollout history命令,查看Deployment的历史信息
# kubectl rollout history deployment hello-deployment
上面提到RC在rolling-update升级成功后不能直接回滚,而使用Deployment却可以回滚到上一版本,但要加上–revision参数,指定版本号
# kubectl rollout history deployment hello-deployment –revision=2
使用rollout undo回滚到上一版本
# kubectl rollout undo deployment hello-deployment
使用–to-revision可以回滚到指定版本
# kubectl rollout undo deployment hello-deployment –to-revision=2
四,Volume
在Docker中,容器中的数据是临时的,当容器被销毁时,其中的数据将会丢失。如果需要持久化数据,需要使用Docker数据卷挂载宿主机上的文件或者目录到容器中。Docker中有docker Volume的概念,Docker的Volume只是磁盘中的一个目录,生命周期不受管理。当然Docker现在也提供Volume将数据持久化存储,但支持功能比较少(例如,对于Docker 1.7,每个容器只允许挂载一个Volume,并且不能将参数传递给Volume)。
在Kubernetes中,当Pod重建的时候,数据也会丢失,Kubernetes也是通过数据卷挂载来提供Pod数据的持久化的。Kubernetes数据卷是对Docker数据卷的扩展,Kubernetes数据卷是Pod级别的,可以用来实现Pod中容器的文件共享。Kubernetes Volume具有明确的生命周期 – 与pod相同。因此,Volume的生命周期比Pod中运行的任何容器要持久,在容器重新启动时可以保留数据,当然,当Pod被删除不存在时,Volume也将消失。注意,Kubernetes支持许多类型的Volume,Pod可以同时使用任意类型/数量的Volume。
要使用Volume,pod需要指定Volume的类型和内容(spec.volumes字段),和映射到容器的位置(spec.containers.volumeMounts字段)。
容器中的进程可以看到Docker image和volumes组成的文件系统。Docker image处于文件系统架构的root,任何volume都映射在镜像的特定路径上。Volume不能映射到其他volume上,或者硬链接到其他volume。容器中的每个容器必须堵路地指定他们要映射的volume。
Kubernetes支持Volume类型有很多,详细可以参考https://www.cnblogs.com/guyeshanrenshiwoshifu/p/9044655.html
五,service
Service是定义一系列Pod以及访问这些Pod的策略的一层抽象。因为Service是抽象的,所以在图表里通常看不到它们的存在。
Service通过Label找到Pod组。当你在Service的yaml文件中定义了该Service的selector中的label为app:my-web,那么这个Service会将Pod–>metadata–>labeks中label为app:my-web的Pod作为分发请求的后端。当Pod发生变化时(增加、减少、重建等),Service会及时更新。这样一来,Service就可以作为Pod的访问入口,起到代理服务器的作用,而对于访问者来说,通过Service进行访问,无需直接感知Pod。
Service的目标是提供一种桥梁, 它会为访问者提供一个固定访问地址,用于在访问时重定向到相应的后端,这使得非 Kubernetes原生应用程序,在无须为Kubemces编写特定代码的前提下,轻松访问后端。
需要注意的是,Kubernetes分配给Service的固定IP是一个虚拟IP,并不是一个真实的IP,在外部是无法寻址的。真实的系统实现上,Kubernetes是通过Kube-proxy组件来实现的虚拟IP路由及转发。所以在之前集群部署的环节上,我们在每个Node上均部署了Proxy这个组件,从而实现了Kubernetes层级的虚拟转发网络。有一个特别类型的Kubernetes Service,称为’LoadBalancer’,作为外部负载均衡器使用,在一定数量的Pod之间均衡流量。比如,对于负载均衡Web流量很有用。
现在,假定有2个后台Pod,并且定义后台Service的名称为‘backend-service’,lable选择器为(tier=backend, app=myapp)。backend-service 的Service会完成如下两件重要的事情:
(1)会为Service创建一个本地集群的DNS入口,因此前端Pod只需要DNS查找主机名为 ‘backend-service’,就能够解析出前端应用程序可用的IP地址。
(2)现在前端已经得到了后台服务的IP地址,但是它应该访问2个后台Pod的哪一个呢?Service在这2个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个。通过每个Node上运行的代理(kube-proxy)完成。
1,Service代理外部服务
Service不仅可以代理Pod,还可以代理任意其他后端,比如运行在Kubernetes外部Mysql、Oracle等。这是通过定义两个同名的service和endPoints来实现的。示例如下:
redis-service.yaml
apiVersion: v1
kind: Service
metadata:
name: redis-service
spec:
ports:
- port: 6379
targetPort: 6379
protocol: TCP
redis-endpoints.yaml:
apiVersion: v1
kind: Endpoints
metadata:
name: redis-service
subsets:
- addresses:
- ip: 10.0.251.145
ports:
- port: 6379
protocol: TCP
基于文件创建完Service和Endpoints之后,在Kubernetes的Service中即可查询到自定义的Endpoints。
[root@k8s-master demon]# kubectl describe service redis-service
Name: redis-service
Namespace: default
Labels:
Selector:
Type: ClusterIP
IP: 10.254.52.88
Port: 6379/TCP
Endpoints: 10.0.251.145:6379
Session Affinity: None
No events.
[root@k8s-master demon]# etcdctl get /skydns/sky/default/redis-service
{"host":"10.254.52.88","priority":10,"weight":10,"ttl":30,"targetstrip":0}
2,Service内部负载均衡
当Service的Endpoints包含多个IP的时候,及服务代理存在多个后端,将进行请求的负载均衡。默认的负载均衡策略是轮训或者随机(有kube-proxy的模式决定)。同时,Service上通过设置Service–>spec–>sessionAffinity=ClientIP,来实现基于源IP地址的会话保持。
3,发布Service(非常重要,着重理解并操作)
Service的虚拟IP是由Kubernetes虚拟出来的内部网络,外部是无法寻址到的。但是有些服务又需要被外部访问到,例如web前段。这时候就需要加一层网络转发,即外网到内网的转发。Kubernetes提供了NodePort、LoadBalancer、Ingress三种方式。
(1)NodePort,在之前的Guestbook示例中,已经延时了NodePort的用法。NodePort的原理是,Kubernetes会在每一个Node上暴露出一个端口:nodePort,外部网络可以通过(任一Node)[NodeIP]:[NodePort]访问到后端的Service。即使某一个node上没有pod,也会通过该node的ip:port方式转发到有pod的node上进行访问。
(2)LoadBalancer,在NodePort基础上,Kubernetes可以请求底层云平台创建一个负载均衡器,将每个Node作为后端,进行服务分发。该模式需要底层云平台(例如GCE)支持。
(3)Ingress,是一种HTTP方式的路由转发机制,由Ingress Controller和HTTP代理服务器组合而成。Ingress Controller实时监控Kubernetes API,实时更新HTTP代理服务器的转发规则。HTTP代理服务器有GCE Load-Balancer、HaProxy、Nginx等开源方案。
4,servicede 自发性机制
Kubernetes中有一个很重要的服务自发现特性。一旦一个service被创建,该service的service IP和service port等信息都可以被注入到pod中供它们使用。Kubernetes主要支持两种service发现 机制:环境变量和DNS。
(1)环境变量方式
Kubernetes创建Pod时会自动添加所有可用的service环境变量到该Pod中,如有需要.这些环境变量就被注入Pod内的容器里。需要注意的是,环境变量的注入只发送在Pod创建时,且不会被自动更新。这个特点暗含了service和访问该service的Pod的创建时间的先后顺序,即任何想要访问service的pod都需要在service已经存在后创建,否则与service相关的环境变量就无法注入该Pod的容器中,这样先创建的容器就无法发现后创建的service(被坑过)。
(2)DNS方式
Kubernetes集群现在支持增加一个可选的组件——DNS服务器。这个DNS服务器使用Kubernetes的watchAPI,不间断的监测新的service的创建并为每个service新建一个DNS记录。如果DNS在整个集群范围内都可用,那么所有的Pod都能够自动解析service的域名。
5,多个service如何避免地址和端口冲突
此处设计思想是,Kubernetes通过为每个service分配一个唯一的ClusterIP,所以当使用ClusterIP:port的组合访问一个service的时候,不管port是什么,这个组合是一定不会发生重复的。另一方面,kube-proxy为每个service真正打开的是一个绝对不会重复的随机端口,用户在service描述文件中指定的访问端口会被映射到这个随机端口上。这就是为什么用户可以在创建service时随意指定访问端口。
6,service目前存在的不足
Kubernetes使用iptables和kube-proxy解析service的入口地址,在中小规模的集群中运行良好,但是当service的数量超过一定规模时,仍然有一些小问题。首当其冲的便是service环境变量泛滥,以及service与使用service的pod两者创建时间先后的制约关系。目前来看,很多使用者在使用Kubernetes时往往会开发一套自己的Router组件来替代service,以便更好地掌控和定制这部分功能。
原文转载于:https://www.cnblogs.com/guyeshanrenshiwoshifu/p/9044655.html 并做了一部分修改和补充。
转载请注明:西数超哥博客www.ysidc.top» k8s入门系列之概念深入篇
https://www.ysidc.top 西数超哥博客,数据库,西数超哥,虚拟主机,域名注册,域名,云服务器,云主机,云建站,ysidc.top