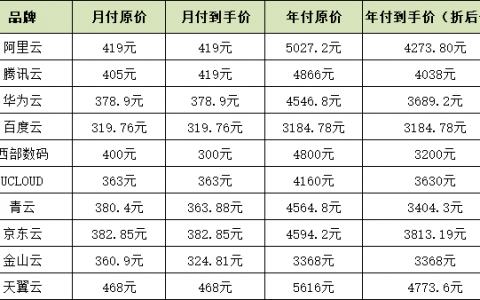
12月13日,2018数据资产管理大会在北京国家会议中心举行。本次大会由中国信息通信研究院、中国通信标准化协会(CCSA)主办,CCSA TC601大数据技术标准推进委员会承办,中国IDC圈协办。
会上中国信息通信研究院大数据团队做了TC601成果汇报,以下为演讲实录:

中国信息通信研究院大数据团队
由四位同事给大家讲解除了数据资产管理之外的几个成果,我们有请闫树、王卓、王妙琼、和马鹏玮,先是闫树来讲讲知识图谱的一个标准。
闫树:各位专家大家下午好,今天我代表知识图谱的标准编写组向大家发布知识图谱技术要求与测试方法的标准。知识图谱是在数据走向智能路径上非常关键的一环,它能帮助用户迅速、准确地查找到自己需要的信息,而且它的技术和产品正在成为大数据管理、数据分析和价值挖掘乃至智能领域一个非常重要的支撑,所以我们跟部分业界的知识图谱的厂商共同完成这样一个知识图谱技术要求与测试方法的标准。
标准就是结合了业界的需求,针对我们通用知识图谱的这些基础的功能和性能的一些指标,规定了七大类的技术要求。比如像数据接入,就是知识图谱工具从数据角度怎么样读入数据、接入数据。元数据定义,知识图谱工具定义实体元数据、关系元数据等的能力,以及抽取实体属性关系需要满足的功能,比如说数据抽取过程中有哪些关键的环节需要知识图谱这个工具完成的。还有数据存储与查询,包括知识图谱在数据存储、查询、更新、删除、过滤以及历史状态回溯这么一系列方面需要满足的能力。数据融合,数据推理与分析还有知识图谱展示,包括一些可视化的展示,加载、导出和配置的能力。我们在制作这个标准的时候,知识图谱的业界的企业在通用知识图谱这些功能上和定位上其实都是不太一样的,有些企业会把知识图谱作为底层架构为它其他的产品服务,有的会把知识图谱作为关键的产品,有的在可视化方面会具有一些特色,而有的就不太重视可视化的功能。所以我们这28个具体的指标有一些是必选的、有一些是可选的,还有一些是必选加可选的,就是我们认为这个功能应该具备,但是具体的实践方式我们可能有多种多样的选择。
知识图谱的参与厂商包括北京海致星图、明略、文因互联、智言科技、搜狗、中移苏研,等等感谢这些厂商,接下来由我的同事王妙琼来介绍下一个标准。
王妙琼:大家下午好,又见面了,我是来自中国信通院大数据团队的王妙琼。这边我给大家介绍一下流计算标准的情况,说到流计算大家脑海里面会蹦出来一些开源的名词,像Storm、Spark Streaming、Flink,这些技术架构都是解决一些实时数据的处理和分析的问题,使具有实效性的数据能发挥它最大的价值。
那当一个企业需要去建设一些实时数据应用的时候,我们该怎么去选择这些技术产品呢?我们有这么多产品,怎么找到符合自己要求的一些基础功能,我要求它运行要稳定,又要使用便捷,所以我们找到了业界八个在流计算领域有深入研究的企业来和我们共同来制定了这个标准,去定义一个优秀的流计算产品应该是什么样子的。我们这个标准是国内首个聚焦于分布式流计算平台技术要求的规范,里面定义了流计算平台相关的术语,规定了7大类的技术要求和51项具体技术指标。明年我们也会依据这项标准开展我们第一批流计算的测试,后续也会围绕流计算去做一些白皮书这类知识普及性的工作,以及流计算产品性能方面的标准。
这里我们要特别感谢一下参与流计算标准的这些企业,他们分别是百度云、阿里云、腾讯云、网易、华为、国双、星环和中移苏研,在这里感谢大家的支持。
王卓:大家好,我是来自中国信通院大数据团队的王卓,这里我为大家介绍一下我们时序数据库这个标准目前的情况。首先时序数据实际上是我们工业企业的血液一样的存在,对于时序数据的应用和分析实际上也是工业互联网应用中一个非常重要的环节。
目前对于工业领域的这些需求我们有时序数据库产品来进行解决,时序数据库有非常突出的写入性能,同时针对于时序数据的存储、查询和分析都有一些相应的优化。它能够解决目前大部分工业企业对于传感器数据写入和存储的需求,同时也能够应用在一些传统的运维监控场景上。
市面上已经有很多各种各样的国产分布式时序数据库产品,但这些时序数据库产品依旧是处于比较初级的阶段,还存在诸如功能不完善、技术能力差异较大等等一系列问题,因此我们联合了产业内比较优秀的几家时序数据库生产厂商共同编写了时序数据库的标准。
这项标准融合了互联网领域分布式时序数据库以及传统工业领域的实时数据库共性的一些要求,一共规定了七大类的技术要求和38项具体的技术指标。我们也会根据这些技术指标进行相应的测试。
接下来我们还要感谢参与这一次时序数据库标准编写的单位。本标准由我们中国信通院牵头,同时由百度云、阿里云、腾讯云、网易、华为、陶思数据、朗坤智慧共同编写完成。
实际上今年我们已经完成了时序数据库产品的第一批测试,这批测试根据我们的标准主要针对于时序数据库的基础能力。接下来明年我们会继续根据时序数据库性能的一些要求制定相应的标准并开展测试,谢谢大家。
最后,由我们的同事马鹏玮来介绍关系型云数据库项目的进展情况。
马鹏玮:大家好,我是来自信通院大数据部的马鹏玮,很感谢在这里能有这个机会为大家介绍一下我们这个关系型云数据库的项目,其实大家看这个名字大概能看出来这个东西是干什么的,它有两个特点,第一个是关系型,第二是云,界定了这个数据库的范围,不是我们讨论的比如上午讲到的分布式事务数据库、时序数据库也不是集中式关系型数据库。
我来简单介绍一下这个项目背景,数据库作为企业的一个核心的IT基础设施是大家有目共睹的,可以说大家基本上每年采购软件的费用大概在60-70%左右都是花在数据库上面,包括维护、包括服务、包括采购、包括更新,关系型数据库是信息软件成本里面的重中之重,在新的场景下我们现在因为数据爆炸,传统来说只能建机房完成服务,所以我觉得机房产业真的是非常发达,因为它契合了大家的痛点,因为数据太爆炸了,这个需求特别旺盛。
但是很多公司自己是没有建机房的一些能力的,所以就借用云的能力,所以我们就根据需求提出了这个项目,就是信息服务的规模和模式已经产生了巨大的变革,这对各企业内部的数据库管理模式服务模式都提出了新的要求。原有的集中型的三大特点跟云对比,第一是资源管理,原有的集中型资源管理是需要耗时耗力,自己要去部署装机房,等等这都很耗精力。第二运维很复杂,安装完了后续如果出问题人得过去。还有成本代价,硬件成本、软件成本工程师成本,这个成本会堆得很高。我们的理想是后面三个,资源统一管理、轻量运维、低成本,这个不跟大家细解释了,这是我们理想中的优化方案,这三个特点正好是关系型云数据库的特点,所以这是未来的必由之路。但是从左边到右边是有问题的,第一个我们概念认知不清楚,有的人问我关系型云数据库到底是个数据库还是云上装了个软件,还是什么之类的,这是概念认知的问题。第二是产业现状的调研分析,到底多少人在用,到底哪些人在用。三是技术能力的基准规范、迁移实施方案经验、不同场景应用特点,这些都是我们欠缺的,所以这些问题都是在我们这本白皮书里面解决掉的。
简单看一下白皮书的大纲,一共分了五个章节,第一是关系型云数据库的概述,第二是关系型云数据库各行业的需求,包括游戏、金融、电信、政务、物流、电商,基本上就是头部行业都覆盖到了。第三关系型云数据库关键能力及验证方法。四是关系型云数据库对传统业务方式的改变。五是关系型数据库云化方案实施路径,这是教大家怎么做,怎么做计划书、指导思想、业务怎么迁移。
我介绍一下这本白皮书的编写组,大家看到所有一线关系型云数据库的服务商都在里面,百度云、阿里云、腾讯云、华为云、金山云、京东云等等这些知名的公司都参与到白皮书的编写里面,这个白皮书非常的重磅,大家有兴趣可以来找我聊。
关系型云数据库的未来计划有四个点,第一梳理产业发展现状,第二研讨发展痛点及问题,第三建立关系型云数据库应用方服务方互动平台,可以把各自的痛点一起聊一聊而不是各说各的,大家都联系不到一起,不能解决问题,第四是制定关系型云数据库技术管理规范,更长远一点我们会根据这个标准规范定出基础能力和性能每个月给大家发一个月报和产业的整体趋势大家看一下究竟这个东西能不能用,能不能用好。
谢谢大家。